Bayesian Optimization using a Quantum Gaussian Process Surrogate Model
In this notebook, we will perform a Bayesian Optimization by using sQUlearn’s implementations of Quantum Gaussian Processes squlearn.kernel.QGPR and Fidelity Kernels squlearn.kernel.FidelityKernel.
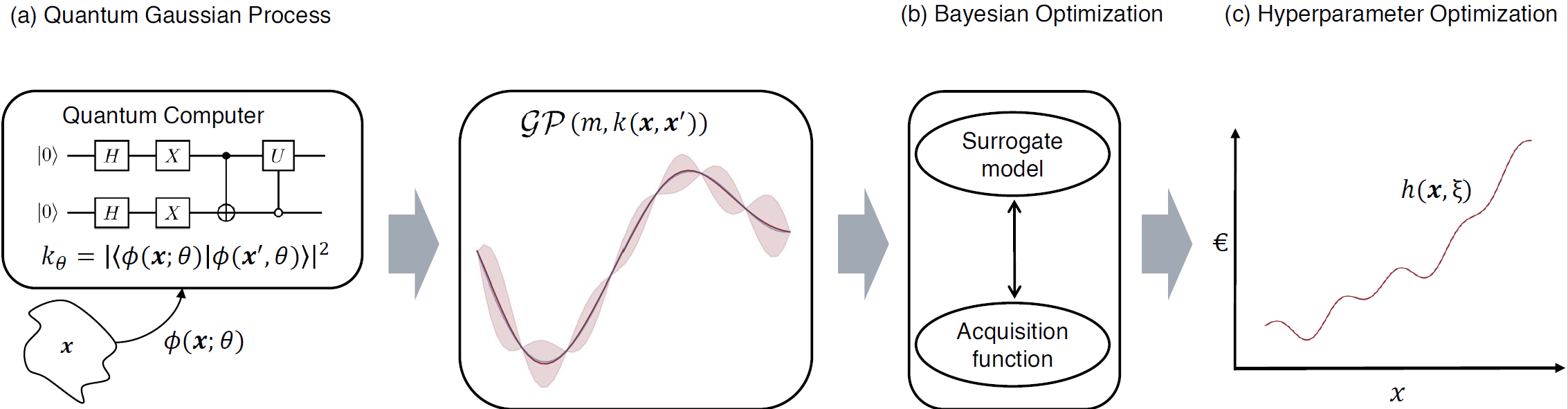
Fig. 1: Conceptual layout of a quantum Bayesian optimization using a QGPR surrogate, taken from Rapp, F., Roth, M.
Bayesian optimization is a global optimization method that solves problems of the form
The optimization proceeds iteratively, selecting the next sample based on information gathered from previous iterations. This informed approach typically demands only a modest number of samples, rendering it appealing for scenarios where evaluating \(g\) is expensive. By treating \(g\) as a black-box, Bayesian optimization imposes no constraints on its functional form.
The algorithm starts by randomly selecting a sample and creating a surrogate model to represent \(g\). Subsequent samples are chosen based on a balance between exploiting known information and exploring new areas, quantified by an acquisition function. This process is iterated to improve the accuracy of the surrogate model in approximating the true function. Gaussian process models are often preferred for surrogates due to their posterior variance output. A common choice for an acquisition function is the expected improvement (EI)
Here \(\mu(\boldsymbol{x})\) and \(\Sigma(\boldsymbol{x})\) are the posterior mean prediction and the prediction uncertainty of the surrogate model at position \(\boldsymbol{x}\), and \(\varphi(Z)\), and \(\boldsymbol{\Phi}(Z)\) are the probability distribution and the cumulative distribution of the standard normal distribution. The location of the best sample, i.e., the current observed minimum of the surrogate model, is indicated by \(\boldsymbol{x}^+\). The standardized prediction error \(Z\) is given by \(Z = [f(\boldsymbol{x}^+) - \mu(\boldsymbol{x}) - \lambda]/\Sigma(\boldsymbol{x})\) if \(\Sigma(\boldsymbol{x}) > 0\) and \(Z=0\) if \(\Sigma(\boldsymbol{x}) = 0\). The parameter \(\lambda\) is a hyperparameter that controls the exploitation-exploration trade-off, where a high value of \(\lambda\) favours exploration.
We obtain a quantum Bayesian optimization (QBO) algorithm by using a QGP model as a surrogate model.
The follwing example will adapt the structure of the examples made in scikit-optimize.
We start by defining the Bayesian optimization base class.
[1]:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize, OptimizeResult, Bounds
from scipy.stats import norm
class BayesOpt:
def __init__(
self,
f,
domain,
surrogate_model,
random_state,
nr_initial_points=None,
X_plot=None,
Y_plot=None,
acquisition="EI",
xi=0.01,
plot_iters=False,
):
self.surrogate = surrogate_model
self.acquisition = acquisition
self.blackbox_function = f
self.xi = xi
self.rnd = random_state
self.bounds = Bounds([d[0] for d in domain], [d[1] for d in domain])
self._initial_samples = np.random.uniform(
self.bounds.lb, self.bounds.ub, size=(nr_initial_points, len(domain))
)
self.X = self._initial_samples
Y_init = [self.blackbox_function(xi) for xi in self.X]
self.Y = np.array(Y_init).reshape(-1, 1)
self.X_plot = X_plot
self.Y_plot = Y_plot
self.plot_surrogate_acquisition = plot_iters # Control whether to plot at each step
def expected_improvement(self, X, X_sample, Y_sample, gpr):
mu, sigma = gpr.predict(X, return_std=True)
mu_sample = gpr.predict(X_sample)
sigma = sigma.reshape(-1, 1)
mu_sample_opt = np.max(mu_sample)
with np.errstate(divide="warn"):
imp = mu - mu_sample_opt - self.xi
Z = imp / sigma
ei = imp * norm.cdf(Z) + sigma * norm.pdf(Z)
ei[sigma == 0.0] = 0.0
return ei.ravel()
def propose_location(self, acquisition, X_sample, Y_sample, gpr):
dim = len(self.bounds.lb)
min_val = np.inf
min_x = None
def min_obj(X):
# Minimization objective is the negative acquisition function
return -acquisition(X.reshape(-1, dim), X_sample, Y_sample, gpr)
# Find the best optimum by starting from n_restart different random points.
for x0 in np.random.uniform(self.bounds.lb, self.bounds.ub, size=(self.restarts, dim)):
# add a maxiter of 10 to the optimizer
res = minimize(
min_obj, x0=x0, bounds=self.bounds, method="L-BFGS-B", options={"maxiter": 10}
)
if res.fun < min_val:
min_val = res.fun
min_x = res.x
print("next sample X position: ", min_x)
return min_x
def run_optimization(self, n_iter, n_restarts=1):
X_sample = np.array(self.X)
Y_sample = self.Y
self.restarts = n_restarts
self.n_iter = n_iter
if self.acquisition == "EI":
acq_func = self.expected_improvement
for i in range(n_iter):
# Update Gaussian process with existing samples
self.surrogate.fit(X_sample, Y_sample)
X_next = self.propose_location(acq_func, X_sample, Y_sample, self.surrogate)
X_next = np.array([X_next]).reshape(1, -1)
Y_next = [self.blackbox_function(xi) for xi in X_next]
# Add sample to previous samples
X_sample = np.vstack((X_sample, X_next))
Y_sample = np.vstack((Y_sample, Y_next))
# Plot surrogate and acquisition at each step
if self.plot_surrogate_acquisition:
self.plot_surrogate(i, X_sample, Y_sample)
result = OptimizeResult()
best = np.argmin(Y_sample)
result.x = X_sample[best]
result.fun = Y_sample[best]
result.func_vals = Y_sample
result.bounds = self.bounds
result.x_iters = X_sample
return result
def plot_surrogate(self, step, X_sample, Y_sample):
if self.X_plot is None:
raise ValueError("X_plot is None. Surrogate function cannot be plotted.")
y_pred, sigma = self.surrogate.predict(self.X_plot, return_std=True)
plt.title(f"Surrogate Function (Step {step + 1})")
plt.plot(self.X_plot, self.Y_plot, "k--", label="Noise-free objective")
plt.scatter(X_sample, Y_sample, color="red", marker="x", label="Samples")
plt.plot(self.X_plot, y_pred, label="Surrogate function", color="blue")
plt.fill_between(
self.X_plot[:, 0],
y_pred[:, 0] - 1.96 * sigma,
y_pred[:, 0] + 1.96 * sigma,
alpha=0.2,
color="blue",
)
plt.xlabel("X")
plt.ylabel("Surrogate Value")
plt.legend()
plt.show()
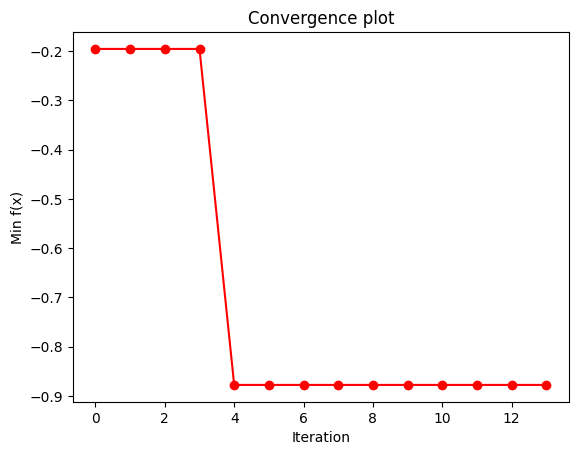
if step == self.n_iter - 1:
y_conv = np.minimum.accumulate(Y_sample)
plt.plot(y_conv, "ro-")
plt.xlabel("Iteration")
plt.ylabel("Min f(x)")
plt.title("Convergence plot")
Note:
In this example, we only used the EI acquisition function. This can be easily exchanged through a customised acquisition function.
There might be some rescaling of the inputs necessary, depending on the choice of data encoding circuit
A custom plot_surrogate function is available, but only if there is an analitically know representation of your objective function
The performance and results can be dependent on the choice of encoding strateg, and its hyperparameters (e.g. number qubits / layers / parameters).
Depending on the number of function samples, the algorithm can run for quite a while. Especially when using a shot based simulator (e.g. QASM)
We will start with 4 random samples and then perform the Bayesian optimization.
[4]:
# perform bayesian optimization with qgpr qBO = BayesOpt( f, domain=[(-2.0, 2.0)], surrogate_model=qgpr_model, random_state=0, nr_initial_points=4, acquisition="EI", xi=0.01, plot_iters=True, X_plot=x, Y_plot=fx, ) result = qBO.run_optimization(n_iter=10)
next sample X position: [-0.83912291]
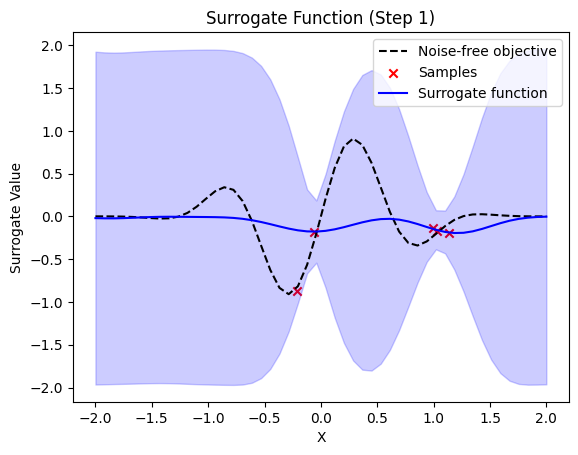
next sample X position: [1.24844729]
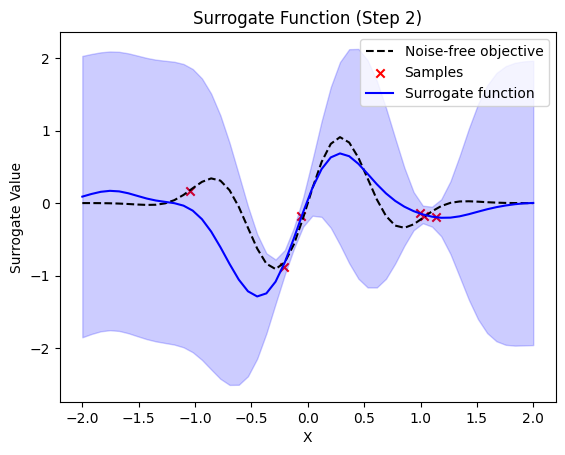
next sample X position: [-0.07670188]
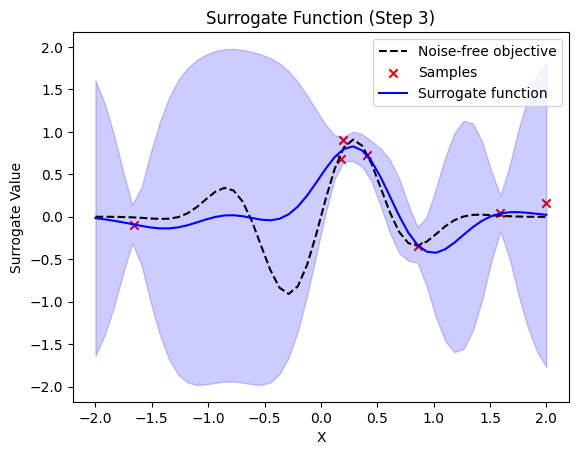
next sample X position: [-0.35654828]
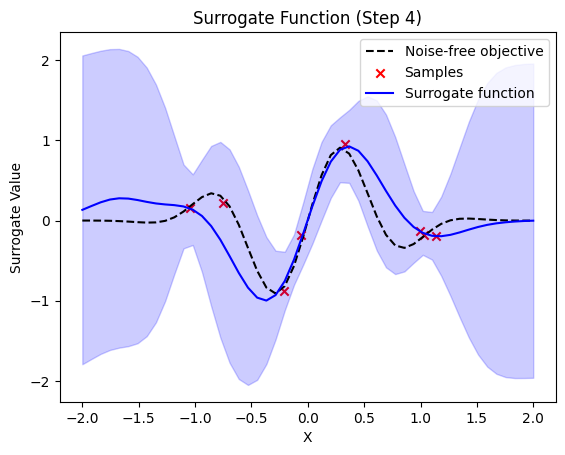
next sample X position: [-0.1134778]
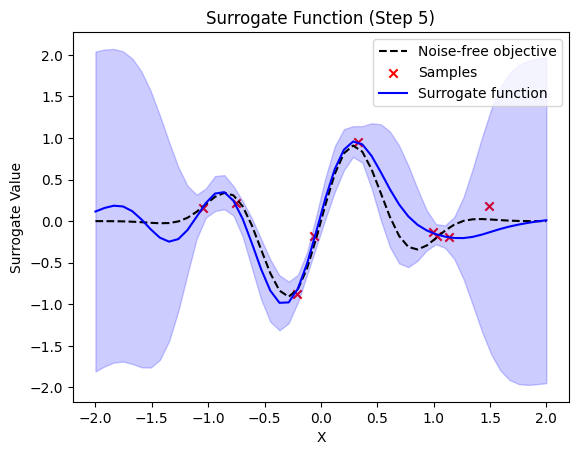
next sample X position: [1.67782542]
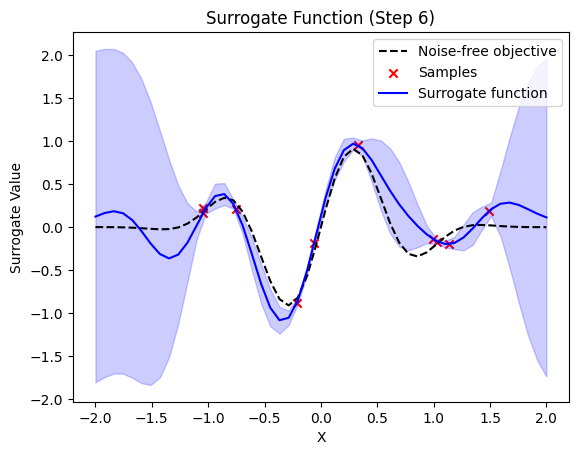
next sample X position: [0.0743701]
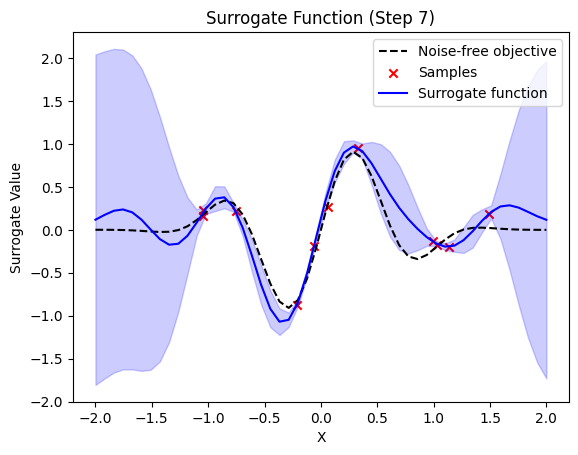
next sample X position: [-1.27912424]
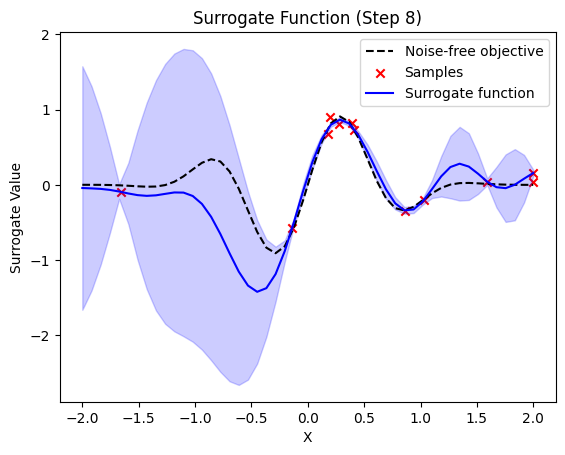
next sample X position: [0.84665542]
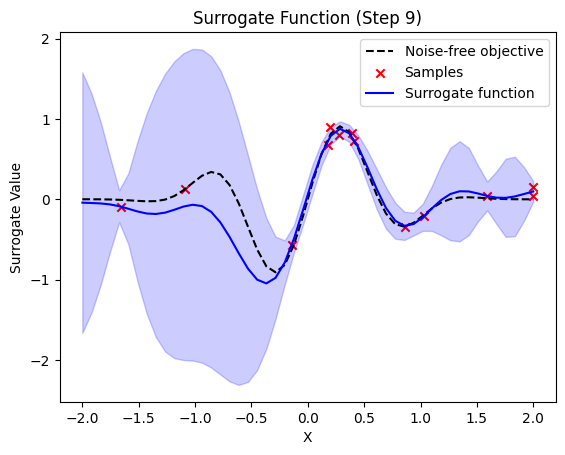
next sample X position: [-1.85580871]
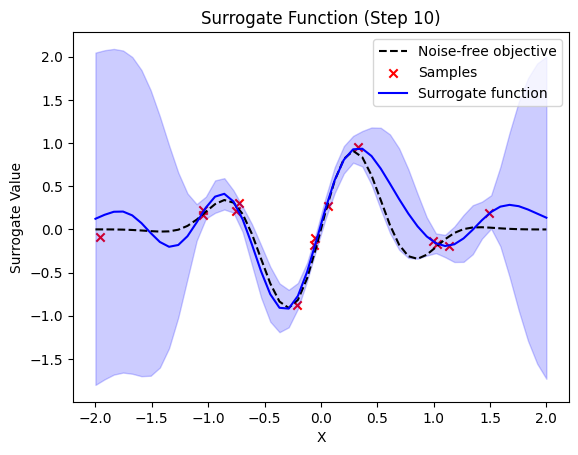
For the QGPR the choice of Projected Quantum Kernels squlearn.kernel.ProjectedQuantumKernel is also possible. The algorithm can also be applied to more sophisticated problems. E.g., we used it to optimize the price prediction of industrial machinery. The intrested reader can learn more about it from our pre-print Quantum Gaussian Process Regression for Bayesian Optimization.
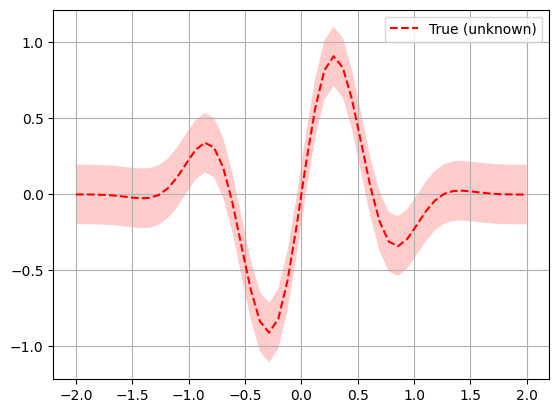
To get an intuition how Bayesian optimization works, we perform it the mimization of a known objective function with noisy samples. This will allow us to plot exactly what happens in each iteration step.
[2]:
# objective function initialization noise_level = 0.1 def f(x, noise_level=noise_level): return np.sin(5 * x[0]) * (1 - np.tanh(x[0] ** 2)) + np.random.randn() * noise_level # Plot f(x) + contours x = np.linspace(-2, 2, 50).reshape(-1, 1) fx = [f(x_i, noise_level=0.0) for x_i in x] plt.plot(x, fx, "r--", label="True (unknown)") plt.fill( np.concatenate([x, x[::-1]]), np.concatenate( ( [fx_i - 1.96 * noise_level for fx_i in fx], [fx_i + 1.96 * noise_level for fx_i in fx[::-1]], ) ), alpha=0.2, fc="r", ec="None", ) plt.legend() plt.grid() plt.show()
[3]:
# create the qgpr surrogate model from squlearn.util import Executor from squlearn.encoding_circuit import HubregtsenEncodingCircuit from squlearn.kernel.lowlevel_kernel import FidelityKernel from squlearn.kernel import QGPR # set up quantum kernel and qgpr num_qubits = 4 enc_circ = HubregtsenEncodingCircuit(num_qubits, num_layers=3) q_kernel = FidelityKernel(encoding_circuit=enc_circ, executor=Executor(), parameter_seed=0) qgpr_model = QGPR(quantum_kernel=q_kernel, sigma=0.01**2)
Note: